Automatic Differentiation for nonlinear operators¶
@Author: Francesco Picetti - picettifrancesco@gmail.com
In this notebook, we build a new kind of operator that leverages a new entry in the PyTorch ecosystem, functorch. Basically, it allows for the computation of the Jacobian-vector product given a function defined with PyTorch primitives.
import torch
import occamypy as o
o.backend.set_seed_everywhere()
try:
from functorch import jvp
except ModuleNotFoundError:
raise ModuleNotFoundError("This submodule requires functorch to be installed. Do it with:\n\tpip install functorch")WARNING! DATAPATH not found. The folder /tmp will be used to write binary files
/nas/home/fpicetti/miniconda3/envs/occd/lib/python3.10/site-packages/dask_jobqueue/core.py:20: FutureWarning: tmpfile is deprecated and will be removed in a future release. Please use dask.utils.tmpfile instead.
from distributed.utils import tmpfile
class OperatorAD(o.Operator):
def __init__(self, domain: o.VectorTorch, range: o.VectorTorch, fwd_fn, background: o.VectorTorch = None, name: str = None):
"""
Generic operator whose forward is defined, and adjoint is computed with automatic differentiation
Args:
domain: operator domain vector
range: operator range vector
fwd_fn: torch-compatible forward function
background: vector in which the Jacobian will be computed
name: function name for print purpose
"""
self.fwd_fn = fwd_fn
# store the vector to be multiplied with the Jacobian
self.domain_tensor = torch.ones_like(domain[:])
# store the domain vector in which the function will be linearized
self.background = background if background is not None else domain
super(OperatorAD, self).__init__(domain=domain, range=range)
self.name = "OperatorAD" if name is None else name
def forward(self, add, model, data):
self.checkDomainRange(model, data)
if not add:
data.zero()
data[:] += self.fwd_fn(model[:])
return
def adjoint(self, add, model, data):
self.checkDomainRange(model, data)
grad = jvp(self.fwd_fn, (self.background[:],), (self.domain_tensor,))[1]
if not add:
model.zero()
model[:] += grad * data[:]
return
def set_background(self, in_content: o.VectorTorch):
"""
Set the background vector in which the Jacobian will be computed
Args:
in_content: background vector
"""
self.background.copy(in_content)
Case 1: linear function ¶
x = o.VectorTorch(torch.tensor([1., 2., 3.]))
print("x =", x)x = tensor([1., 2., 3.])
Forward function
f = lambda x: xAnalytical gradient
g = lambda x: 1.Instantiate the operator
A = OperatorAD(domain=x, range=x, fwd_fn=f, name="x")
print("A is %s" % A.name)A is x
Forward computation:
y = A * x
assert torch.allclose(y[:], f(x[:]))
print("y = f(x) =", y)y = f(x) = tensor([1., 2., 3.])
Adjoint computation:
- set the linearization domain where the gradient is computed (default is the domain vector passed to the
__init__)
A.set_background(x)
print("The gradient ∂f/∂x will be computed at x0 =", A.background)The gradient ∂f/∂x will be computed at x0 = tensor([1., 2., 3.])
- compute the gradient and multiply it with data
z = A.H * y
assert torch.allclose(z[:], g(A.background[:]) * y[:])
print("z = ∂f/∂x0 * y =", z)z = ∂f/∂x0 * y = tensor([1., 2., 3.])
Let's use another linearization point
x0 = x.clone().rand()
A.set_background(x0)
print("The gradient ∂f/∂x0 will be computed on x0 =", A.background)The gradient ∂f/∂x0 will be computed on x0 = tensor([-0.0075, 0.5364, -0.8230])
z = A.H * y
assert torch.allclose(z[:], g(A.background[:]) * y[:])
print("z = ∂f/∂x0 * y =", z)z = ∂f/∂x0 * y = tensor([1., 2., 3.])
As is linear, we can compute the dot product test for operator
A.dotTest(True)Dot-product tests of forward and adjoint operators
--------------------------------------------------
Applying forward operator add=False
Runs in: 0.00019025802612304688 seconds
Applying adjoint operator add=False
Runs in: 0.0007958412170410156 seconds
Dot products add=False: domain=3.146009e-01 range=3.146009e-01
Absolute error: 0.000000e+00
Relative error: 0.000000e+00
Applying forward operator add=True
Runs in: 3.981590270996094e-05 seconds
Applying adjoint operator add=True
Runs in: 0.0004761219024658203 seconds
Dot products add=True: domain=6.292018e-01 range=6.292018e-01
Absolute error: 0.000000e+00
Relative error: 0.000000e+00
-------------------------------------------------
Case 2: nonlinear function ¶
x = o.VectorTorch(torch.tensor([1., 2., 3.]))
print("x =", x)x = tensor([1., 2., 3.])
Forward function
f = lambda x: x * torch.sin(x)Analytical gradient
g = lambda x: x * torch.cos(x) + torch.sin(x)Instantiate the operator
A = OperatorAD(domain=x, range=x, fwd_fn=f, name="x sin(x)")
print("A is %s" % A.name)A is x sin(x)
Forward computation:
y = A * x
assert torch.allclose(y[:], f(x[:]))
print("y = f(x) =", y)y = f(x) = tensor([0.8415, 1.8186, 0.4234])
Adjoint computation:
print("The gradient ∂f/∂x0 will be computed on x0 =", A.background)The gradient ∂f/∂x0 will be computed on x0 = tensor([1., 2., 3.])
z = A.H * y
assert torch.allclose(z[:], g(A.background[:]) * y[:])
print("z = ∂f1/∂x0 * y =", z)z = ∂f1/∂x0 * y = tensor([ 1.1627, 0.1400, -1.1976])
Let's use another linearization point
x0 = x.clone().randn()
A.set_background(x0)
print("The gradient ∂f/∂x0 will be computed on x0 =", A.background)The gradient ∂f/∂x0 will be computed on x0 = tensor([ 0.6472, 0.2490, -0.3354])
z = A.H * y
assert torch.allclose(z[:], g(A.background[:]) * y[:])
print("z = ∂f/∂x0 * y =", z)z = ∂f/∂x0 * y = tensor([ 0.9419, 0.8870, -0.2734])
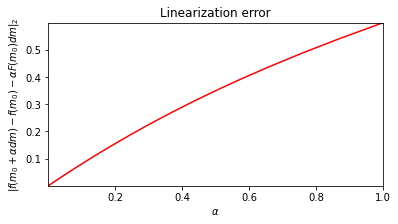
Finally, we can wrap into a NonlinearOperator and compute the linearization test
B = o.NonlinearOperator(A)
_, _ = B.linTest(x, plot=True)